解决 ChatGPT 幻觉问题:利用向量数据库提高回答的准确性
- 作者
在人工智能领域,ChatGPT 以其强大的自然语言处理能力受到广泛关注。它能够流畅地与用户进行交流,回答各种复杂问题。然而,与所有先进的技术一样,ChatGPT 也有其局限性,尤其是在处理信息时偶尔会出现“幻觉”现象,即提供出不基于事实的错觉信息。本文将探讨这一问题以及如何利用向量数据库(如 Milvus)来减少此类错误,从而提高 ChatGPT 回答的可信度。
什么是 AI 幻觉问题?
在 AI 领域,我们用“幻觉”一词来描述系统在没有确凿证据支持的情况下产生错误或捏造出的信息,这类问题主要发生在基于语言模型的 AI 系统中。例如,某些生成型语言模型可能会创造出不存在的数据、统计、历史事件或具体细节等。尽管这些答案在形式上看似合理、自洽,但缺乏真实性和准确性,因此被形容为“一本正经地说废话”。
为什么会出现幻觉问题?
幻觉问题源于 AI 语言模型的训练方式。它们通常是基于海量文本数据进行训练,以学会语言的结构、语法和用法。由于训练资料的复杂多样性,模型无法辨别哪些信息是基于事实的,哪些是虚构的。因此,在没有明确的证据链支持下,模型有时候会基于模式匹配错误地生成答案。
向量数据库的作用
为了缓解这个问题,研究者们开始探索使用像 Milvus 等这样的向量数据库来增强 ChatGPT 的输出准确性。向量数据库是一种专门设计用来存储和处理向量数据的数据库系统。在此上下文中,官方文档、可靠数据源或已验证的信息会被转化为文本向量,并存储在向量数据库中。当用户向 ChatGPT 提问时,它将利用数据库中的向量来搜索并确认答案。
工作流程分析
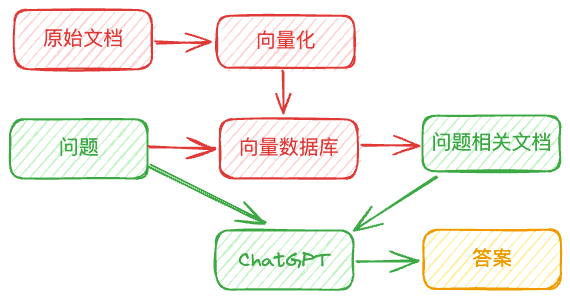
存储文本向量:我们首先将官方文档和可靠数据源通过自然语言处理技术转化为高维文本向量。这些向量在 Milvus 等向量数据库中被适当地组织和索引,为后续的检索做准备。
问题向量化:当用户提出问题时,ChatGPT 将此问题同样转化为向量形式,以便在向量数据库中进行匹配。
搜索相关文档:在响应问题时,ChatGPT 会在 Milvus 等向量数据库中搜索相似的文本向量。如图所示,此过程可被视为一个红色箭头的流程,即根据问题的向量化表示寻找数据库中最接近的向量,从而定位到相应的文档或数据源。
生成准确答案:一旦找到与问题相关的、权威的文档,ChatGPT 则依据正确的上下文来构建其回答。这也标志着绿色箭头所代表的流程——产生了基于可靠信息的准确答案。
预计成效与潜在挑战
使用向量数据库的解决方案,理论上可以大幅度提高 ChatGPT 的答案质量。由于答案是基于官方文档和可靠数据源生成的,故可以确保信息的真实性与准确性。然而,这种方法也面临着一些挑战:例如,需要大量的有效文档来支持广泛主题的查询,这可能涉及版权和信息更新的问题。此外,有时候用户的问题可能是非常具体的,或者答案不在数据库中,这时系统需要更加灵活地处理这类“长尾问题”。
结语
借助向量数据库提升 ChatGPT 的精确性,是一个充满希望的方向。尽管解决方案可能存在一些挑战,但随着技术的迅速发展,我们有理由相信人工智能会逐渐克服“幻觉”问题。这不仅能够提升 ChatGPT 在专业背景下的实用性,也将在更广泛层面上增强公众对 AI 系统的信任。未来的 AI,将更准确、更可信,并以更加贴近人类专家的方式服务于社会。
分享内容