破解密码:驱动现代数据库的关键数据结构(上)
- 作者
🌟 引言:在这个数据驱动的时代,数据库如同现代科技的心脏,承载着海量信息的运转与管理。但是,您是否曾好奇过,支撑这些数据库背后的结构是什么呢?让我们一起探索这些强大的数据结构,并理解它们如何塑造我们的数字世界。这是系列文章的上篇,后面我们会带来系列文章的下篇。
一、B Tree
B树(B Tree)是一种自平衡的搜索树结构,广泛用于数据库索引和文件系统中。
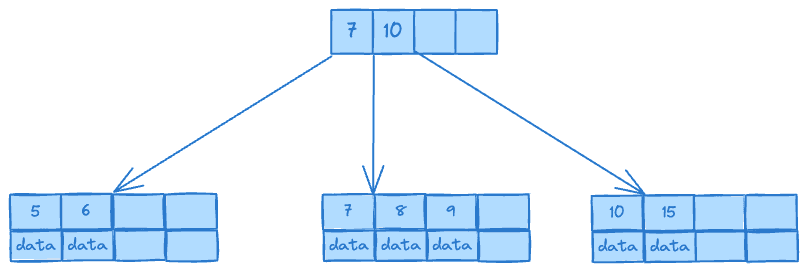
它具有以下特点:
均衡的读写性能:B树保持平衡,使得查询、插入和删除操作的时间复杂度保持在O(log n)级别。这使得在大量数据的情况下,仍能够快速地进行操作。
广泛适用性:B树适用于磁盘基数据库等需要频繁进行数据读写的场景。它的设计考虑了磁盘I/O的特点,通过节点大小合理选择,减少了I/O次数,提高了效率。
多路搜索:B树每个节点可以存储多个键值对,并且有多个子节点。这样可以减少树的深度,加快搜索速度。
自平衡性:通过在插入和删除操作时进行节点分裂和合并来保持树的平衡,使得所有叶子节点位于同一层级。这样可以确保每个查询都需要相似数量级的I/O操作。
支持范围查询:由于B树节点中有多个键值对,并且按序排列,可以方便地进行范围查询操作。
总之,B树作为数据库索引结构,在大规模数据存储和访问的场景中,具有高效的读写性能和广泛的适用性,因此在磁盘基数据库中拥有不可动摇的地位。
二、Inverted Index
倒排索引(Inverted Index)是一种数据结构,用于快速定位文档中的关键词。它是现代搜索引擎如Lucene的基础。
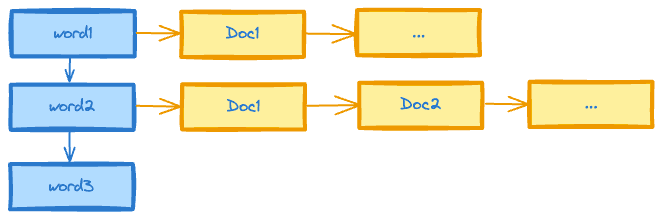
在倒排索引中,每个关键词都与出现该关键词的文档相关联。这个关联可以通过一个指向文档的指针来实现。倒排索引以关键词为索引,每个关键词都有一个对应的包含该关键词的文档列表。
当用户进行检索时,搜索引擎会根据用户输入的关键词在倒排索引中查找相应的文档列表。这样可以快速定位到包含用户查询的关键词的文档。
倒排索引具有高效、快速定位和查询能力。通过使用倒排索引,搜索引擎可以快速地找到包含某个特定关键词的所有相关文档,并按照相关度进行排序。
总之,倒排索引是一种基于关键词和文档之间映射关系构建的数据结构,用于提高搜索引擎的查询效率,并成为现代搜索引擎如Lucene等重要组成部分。
三、Hash Index
哈希索引(Hash Index)是一种在内存数据库中常用的索引结构。它利用哈希函数将键(key)映射到一个固定大小的存储桶(bucket)中,每个桶中存储着对应键值对(key-value pair)的指针或者实际数据。
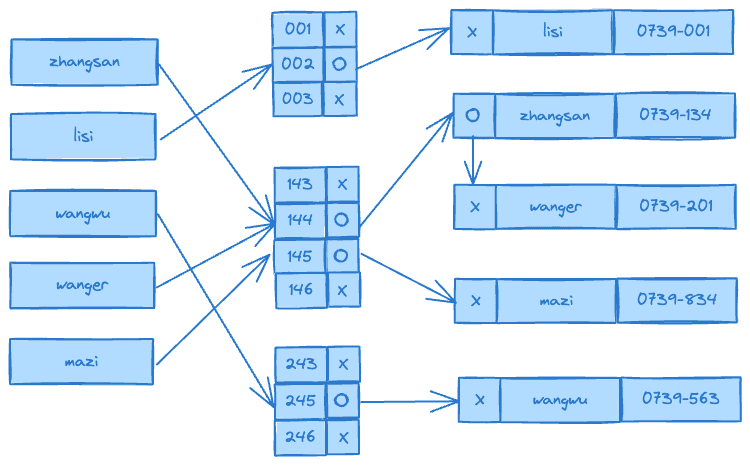
Hash Index具有以下特点:
快速读取:由于使用哈希函数进行映射,Hash Index能够在常数时间内快速定位到特定键所对应的存储桶。因此,通过Hash Index可以快速检索到目标数据。
高效存储:Hash Index通常会使用较小的桶大小,因此它需要较少的内存空间来存储索引。相比其他索引结构如B树(B-tree),Hash Index在内存占用方面更加高效。
然而,Hash Index也存在一些限制和局限性:
仅适用于等值查询:由于哈希函数的特性,Hash Index只能用于等值查询,即根据给定的键查找与之匹配的数据。对于范围查询或排序操作等其他类型的查询,Hash Index并不适用。
冲突问题:当多个键被哈希到同一个桶中时,就会发生冲突。为了解决冲突问题,通常采用开放地址法或者链式法来处理冲突。这可能导致索引的性能下降,尤其是在桶的填充因子较高时。
总的来说,Hash Index在内存数据库中具有快速读取和高效存储的优点,但也受到了查询类型限制和冲突问题等局限性的影响。
四、Prefix Tree
前缀索引(Prefix Tree)是一种适用于字符串检索的索引类型。它使用字符串的前几个字符作为索引的关键字,并记录相关的数据块。前缀索引通常用于进行模糊匹配和前缀查询。
Trie树索引结构示意图:
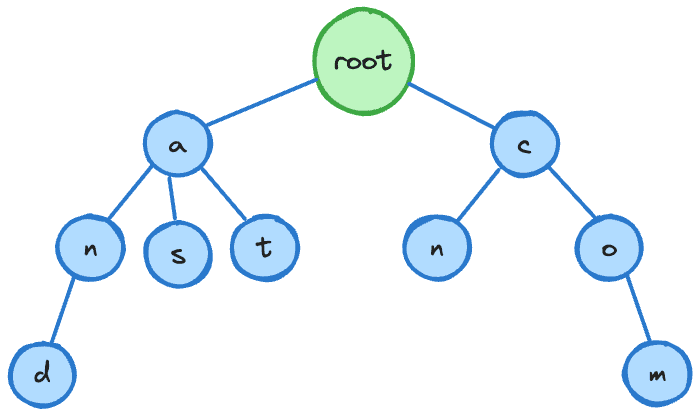
前缀索引在搜索引擎、输入法和数据库中被广泛采用,如MySQL的前缀索引、Elasticsearch的前缀查询等。它们能够提供快速的模糊匹配和前缀查询功能。
五、Sparse Index
稀疏索引(Sparse Index)是一种在数据分布不均匀的情况下优化索引性能的索引类型。它根据数据分布的特点,选择性地存储关键字的索引信息,减少索引的大小和存储开销。
Kafka中稀疏索引结构示意图:
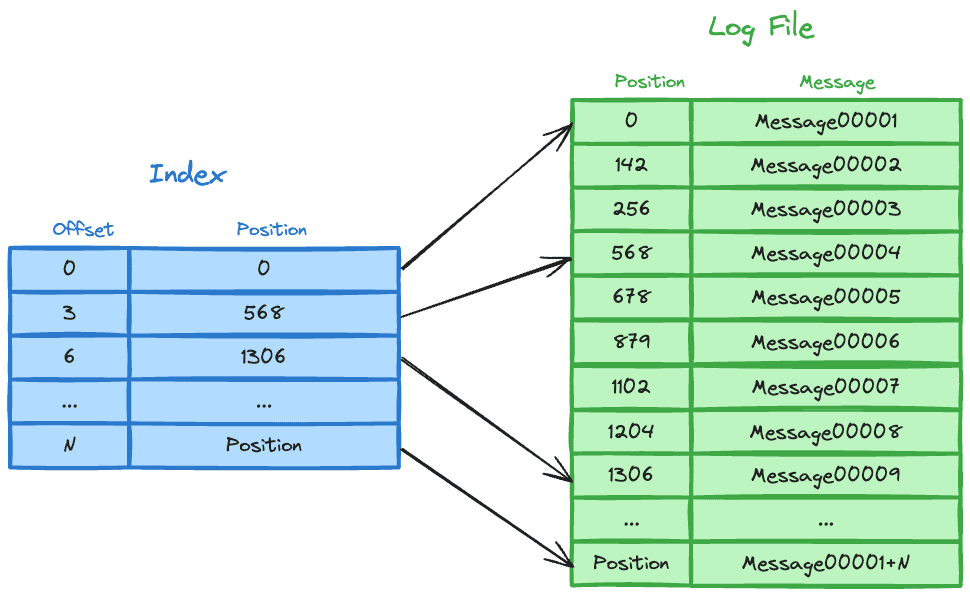
稀疏索引常用于优化空间使用和提高索引性能,如MongoDB和Kafka中的稀疏索引。它们适用于数据分布不均匀的场景,能够提供高效的索引访问。
总结
结合这些结构,我们不难发现,它们各自为王,却又相互依存,共同构建起一幅宏伟的数据库架构图景。这些结构不仅仅是理论上的概念,它们每天都在支撑着我们的网络搜索、社交媒体、在线购物等日常活动。无论是Redis中的实时数据处理,还是Google搜索引擎背后的复杂查询,这些数据结构都扮演着至关重要的角色。
分享内容