- Published on
Supercharge Your Data Processing: Why ClickHouse is a Game-Changer?
- Authors

- Name
- NoOne
Ref: Supercharge Your Data Processing: Why ClickHouse is a Game-Changer?
Clickhouse is one of the most popular OLAP databases nowadays. Although it is well-known, we always have a question in our minds: why do we need Clickhouse? What advantages make big companies like ByteDance and Tencent choose it as their recommended OLAP database? This article will attempt to help us find the answer.
一、What is Clickhouse?
Clickhouse is an open-source OLAP database that uses columnar storage. It was originally developed by Yandex and has now become an independent company called Clickhouse Inc. Its functionality is similar to that of Google Analytics. Its goal is to process trillions of rows and petabytes of data while executing analytical queries quickly.
OLAP databases like Clickhouse are typically used to answer business questions such as "How many people visited Juejin yesterday?" or "How many people visited CSDN yesterday?" If we were to process this using traditional OLTP databases, it could take several minutes or even hours. However, with an OLAP database, we can get the results in milliseconds. The significant speed difference between OLTP and OLAP is due to the different underlying storage structures they use. OLTP databases typically use row-based storage, while OLAP databases typically use columnar storage.
1.1 What is columnar storage?
Let's consider the following data:
| Timestamp | Domain | Visits |
|---|---|---|
| 2022-10-26 12:00 | www.ifb.me | 20 |
| 2022-10-26 12:00 | www.fflow.link | 300 |
| 2022-10-26 12:01 | www.ifb.me | 15 |
| 2022-10-26 12:02 | blog.fflow.link | 21 |
If we were to use OLTP databases like PostgreSQL and MySQL, the data would be stored in the following structure:
Row 1 -> 2022-10-26 12:00, www.ifb.me, 20;
Row 2 -> 2022-10-26 12:00, www.fflow.link, 300;
Row 3 -> 2022-10-26 12:01, www.ifb.me, 15;
Row 4 -> 2022-10-26 12:02, blog.fflow.link, 21;
Each column's data in a row is written adjacently on the disk. This storage structure allows for fast lookup, update, and delete operations on a single row. However, when we need to perform aggregations, such as counting the visits to www.ifb.me, the database will need to read the data row by row and calculate the sum. This not only requires a significant amount of I/O operations but also takes a long time to process.
In contrast, if we were to use a database with columnar storage, the data would be stored in the following structure:
Timestamp column -> 2022-10-26 12:00:001, 2022-10-26 12:00:002, 2022-10-26 12:01:003, 2022-10-26 12:02:004;
Domain column -> www.ifb.me:001, www.fflow.link:002, www.ifb.me:003, blog.fflow.link:004;
Visits column -> 20:001, 300:002, 15:003, 21:004;
In columnar storage, each row of data is stored separately. When we need to count the visits to www.ifb.me, for example, the database would first find the ID corresponding to www.ifb.me in the domain column, and then sum the visit count for that ID in the visits column. The database does not need to retrieve data from multiple disk pages because it only needs to fetch the columns that meet the criteria. This is why analytical queries with columnar storage databases are much faster than with row-based storage databases.
二、Why Clickhouse has changed the game
The main uses of Clickhouse or OLAP databases include, but are not limited to:
- Data analysis
- Data mining
- Business intelligence
- Log analysis
Clickhouse is a database that supports multiple data storage engines. It can import almost any data source into the Clickhouse database and supports fast and flexible drill-down analysis. For example, WeChat currently uses Clickhouse to store log data because logs typically contain a large number of duplicates. Using Clickhouse can achieve a high compression ratio, reducing the storage space occupied by logs. Companies such as Cloudflare, Mux, Plausible, GraphCDN, and Panelbear use Clickhouse to store traffic data and present relevant reports to users in their dashboards. Percona is also using Clickhouse to store and analyze database performance metrics.
三、Scenarios Not Suitable for Clickhouse
Clickhouse cannot replace relational data and is not developed for processing transactional data. Clickhouse is more of a supplement to OLTP and is convenient for data analysis. If you need to update and delete data or perform multi-table joins, Clickhouse is not recommended.
It is also advisable to avoid using Clickhouse as a replica of an OLTP database. Technically, we can synchronize the data from an OLTP database to Clickhouse through events, but the best practice is to use Clickhouse as the only reliable source of data rather than as a mirror of the OLTP database.
四、Why Doesn't MySQL Use Columnar Storage?
- Page-friendly and can store data in leaf nodes, balancing scan and lookup.
- Convenient data updates (which is a drawback for columnar storage, so many OLAP databases do not support updates or support them in complex ways).
- The main bottleneck of transactional databases is I/O. Updating a row of data requires multiple I/O operations in columnar storage, while row-based storage only requires a few.
五、Advantages of Clickhouse
5.1 Active Open Source Community
When evaluating open source software, we must consider whether its community is active. If we use an open source software that suddenly becomes unmaintained, it can be embarrassing, such as the previous case of Alibaba's Dubbo. Of course, this situation is not uncommon in the open source world, so we should try to use open source software backed by large companies/organizations. If we choose to use Clickhouse, we don't have to worry about these issues. Whether it's ByteDance, Tencent, Alibaba in China, or Cloudflare, eBay, Spotify abroad, these well-known companies in the industry are all using Clickhouse.
5.2 Lightning Fast Query Speed
According to Marko Medojevic's report, when analyzing a dataset of 11 million records, Clickhouse's query speed is about 260 times faster than MySQL. However, this comparison may not be fair because MySQL is primarily an OLTP database. But it also indirectly reflects the advantages of OLAP databases.
Clickhouse achieves ultimate performance through its unique database engine, MergeTree, and is inclined to optimize query performance using common hardware.
5.3 Small Indexes (Sparse Indexes)
Everyone knows that indexing is crucial for quickly searching for data in a database. It is best to store indexes in memory for fast access. In OLTP databases, indexes are usually stored using B+ trees, as shown in the image below.
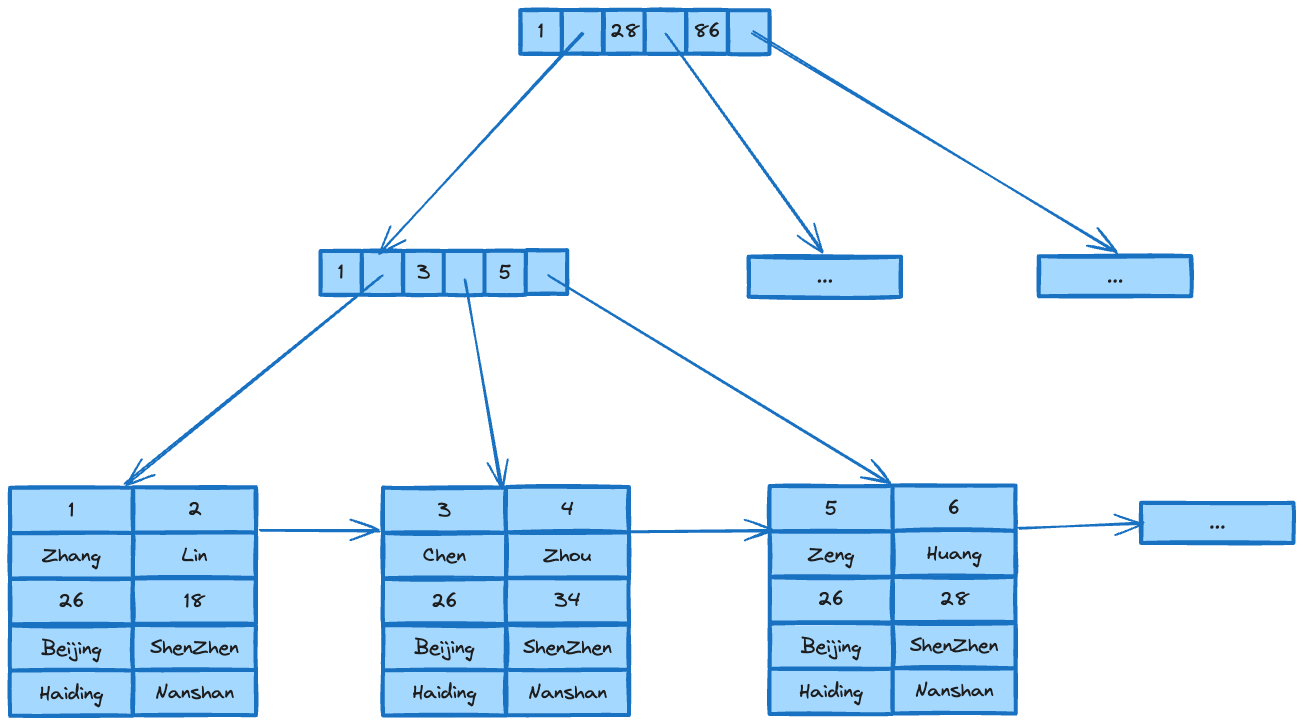
This is suitable for OLTP databases because primary keys are essentially essential. In OLTP databases, it is usually done by querying the database using the primary key ID, for example, SELECT username, email FROM user WHERE id = 10086 or similar queries like UPDATE user SET email = "hunterzhang86@gmail.com" WHERE id = 10086. However, once the data grows to billions of rows and the index no longer fits in memory, the limitations of this type of index become apparent.
In Clickhouse, the index structure is shown in the diagram below.
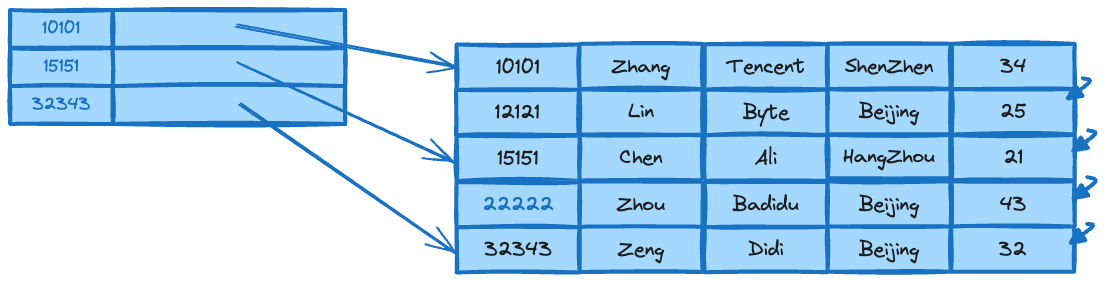
Clickhouse uses indexes similar to Kafka, storing only a subset of index data. The advantage of this approach is that the index is relatively small. Even with a large amount of data, the index can fit in memory. Let's imagine if we want to use the query SELECT SUM(visit) FROM visit WHERE date BETWEEN '2022-10-01' AND '2022-10-31'. A database using sparse indexes would be suitable because our query condition is a date range, not a primary key ID. This is why sparse indexes are frequently used in OLAP databases.
5.4 Data Compression
Due to Clickhouse storing data by column instead of by row, it can compress data better than row-based databases. Some data indicates that placing the same data in Clickhouse requires 70% less disk space compared to PostgreSQL. Additionally, Clickhouse allows specifying compression algorithms and levels for columns conveniently.
5.5 Data TTL
Typically, it is not recommended to store data indefinitely as it would waste a significant amount of disk space. In most cases, setting an appropriate data retention time is a better choice. In Clickhouse, this can be easily achieved by setting the TTL of data when creating a table.
5.6 Supports Multiple Languages
The Clickhouse community is very active, and now it supports SDKs for popular languages like Java, Go, Python, etc. Even for less popular languages like Perl, Clickhouse supports data access through the HTTP interface.
5.7 Horizontal Scalability and High Availability
Clickhouse was built considering horizontal scalability and high availability. We can shard data across multiple nodes and replicate data to another set of servers. Of course, horizontal scalability and high availability add additional complexity. If we deploy Clickhouse using Kubernetes, we can use the Clickhouse Kubernetes Operator for configuration.
六、Conclusion
To be honest, if there is a data analysis scenario now, the first solution I think of is using Clickhouse. Combined with open source BI tools like Superset, we can quickly build a lightweight data analysis system. This is sufficient for most small and medium-sized companies. Finally, if you want to try it quickly, I recommend using Docker for installation.
$ docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 yandex/clickhouse-server
$ docker exec -it clickhouse-server clickhouse-client
Share this content