- Published on
开源数据库对决:Postgres vs MySQL,哪个更适合你的项目?
- Authors

- Name
- NoOne
最近项目里面有要求使用 PostGreSQL,但是之前使用的比较多的是 MySQL,所以花了一些时间对两种数据库做了一些对比。
基础知识
索引是一种数据结构(主要是 B+树),它允许通过节点层搜索键,这些节点被数据库实现为页。树的遍历可以排除不包含结果的页,并缩小包含结果的页范围。这一过程持续到找到包含键的叶子页为止。
叶子节点或页包含一个有序键及其值的列表。当找到一个键时,你就可以获取它的值,这个页被缓存在数据库共享缓冲区中,未来的查询可能请求同一页中的键。
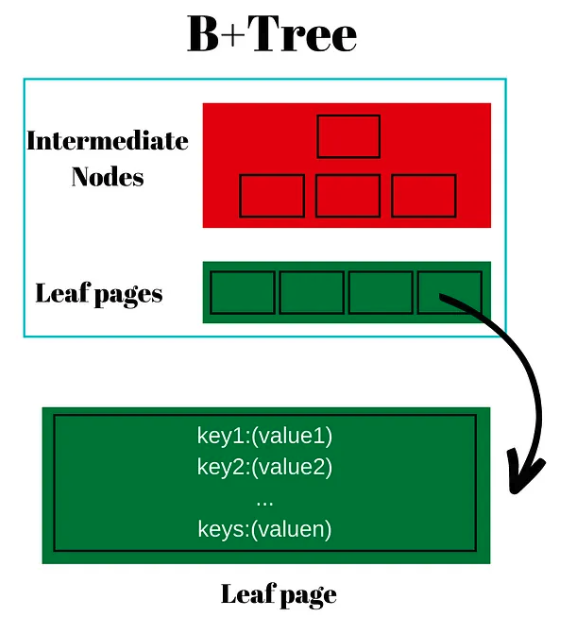
这最后一句话是对所有数据库工程、管理、编程和建模的基本理解。知道你的查询命中了页中相邻的键将最小化 I/O,并提高性能。
B+树索引中的键是创建索引的表上的列,值则是不同数据库不同实现的地方。让我们探讨一下 PostgreSQL 和 MySQL 中的值是什么。
MySQL
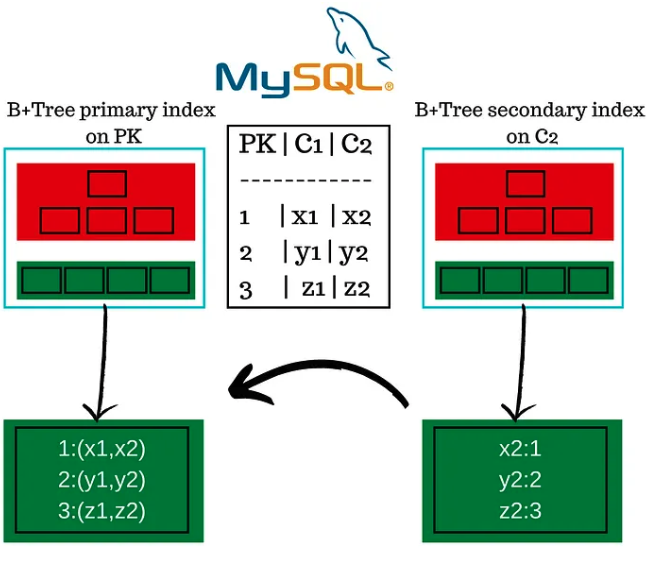
在主索引中,值是包含所有属性的完整行对象。这就是为什么主索引通常被称为聚簇索引,或者我更喜欢的另一个术语——索引组织表。这意味着主索引就是表。
注意这是针对行存储的,数据库可能使用不同的存储模型,如列存储、图或文档,从根本上说这些都可能是潜在的值。
如果你在主索引中查找一个键,你会找到该键所在的页及其值,即该键的完整行,不需要更多 I/O 来获取额外的列。
在辅助索引中,键是你索引的任何列,值是指向完整行实际所在位置的指针。辅助索引叶子节点的值通常是主键。
在 MySQL 中,所有表都必须有一个主索引,所有额外的辅助索引都指向主键。如果你不为 MySQL 表创建主键,系统会为你创建一个。
下图是 MySQL 中的 InnoDB 所有表必须有一个聚簇主索引的示例:
PostgreSQL
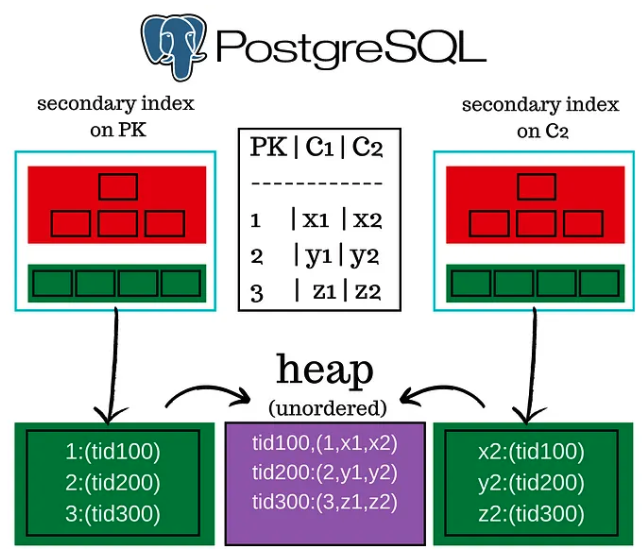
在 PostgreSQL 中,技术上没有主索引,所有索引都是辅助的,都指向系统管理的元组 ID,这些 ID 被加载到堆中。表数据在堆中是无序的,不像主索引叶子节点那样有序。所以如果你插入 1-100 行,它们都在同一个页中,然后更新 1-20 行,这 20 行可能跳到另一个页,变得无序。而在聚簇主索引中,插入必须进入满足键顺序的页。这就是为什么 PostgreSQL 表通常被称为“堆组织表”,而不是“索引组织表”。
需要注意的是,PostgreSQL 中的更新和删除实际上是插入。每次更新或删除都会创建一个新的元组 ID,旧的元组 ID 会因为 MVCC(多版本并发控制)的原因而保留。我稍后会在文章中探讨这一点。
事实上,仅有元组 ID 是不够的。我们实际上需要元组 ID 和页号,这被称为 c_tid。在 MySQL 中不需要这么做,因为我们实际上是在查找主键对应的页。而在 PostgreSQL 中,我们只能通过 I/O 来获取完整行。
PostgreSQL 表是堆组织的,所有索引都指向元组 ID 的示例:
查询比较
以下是针对下面的例子的表。
#TABLE T;
#PRIMARY INDEX ON PK AND SECONDARY INDEX ON C2, NO INDEX ON C1
# C1 和 C2 是文本
# PK 是整数
| PK | C1 | C2 |
|----|----|----|
| 1 | x1 | x2 |
| 2 | y1 | y2 |
| 3 | z1 | z1 |
让我们比较一下 MySQL 和 PostgreSQL 的情况
SELECT * FROM T WHERE C2 = 'x2';
在 MySQL 中,这个查询将花费我们两次 B+树查找。我们首先需要使用辅助索引查找 x2,找到 x2 的主键,即 1,然后再在主索引上查找 1,找到完整行,以便返回所有属性。
*有人可能会认为这只是两次 I/O,但实际上并非如此,B+树查找是 O(logN),根据树的大小,可能会导致多次 I/O。尽管大多数 I/O 可能是逻辑上的(命中共享缓冲区中的缓存页),但了解这种差异很重要。
在 PostgreSQL 中,查找任何辅助索引只需要一次索引查找,然后是一个常数级的单个 I/O 到堆中,获取包含完整行的页。当然,一次 B+树查找比两次查找要好。
为了让这个例子更有趣,假设 C2 不是唯一的,有多个 x2 的条目,那么我们会发现大量与 x2 匹配的 tids(或在 MySQL 中的 PKs)。问题是这些行 ID 会在不同的页中,导致随机读取。在 MySQL 中,这将导致索引查找(或许规划者可能会选择基于这些键的量进行索引扫描而不是查找,但两个数据库都会导致许多随机 I/O。
PostgreSQL 试图通过使用位图索引扫描来最小化随机读取,将结果分组为页而不是元组,并尽可能少的 I/O 来从堆中获取页。后续会应用额外的过滤来呈现候选行。
让我们来看一个不同的查询。
SELECT * FROM T WHERE PK BETWEEN 1 AND 3;
在主键索引上的范围查询中,MySQL 是赢家。通过一次查找,我们可以找到第一个键,并沿着 B+树连接的叶子页走动,找到附近的键,同时找到完整行。
在 PostgreSQL 中,这方面似乎有些吃力。虽然辅助索引查找也会在叶子页上执行同样的 B+树遍历,并找到键,但它只会收集 tids 和页。它的工作还没有结束。PostgreSQL 还需要在堆上进行随机读取,以获取完整行,这些行可能分散在整个堆中,并不是整齐地放在一起,尤其是如果这些行被更新过。频繁的更新是 PostgreSQL 的敌人,为你的表选择一个好的 FillFactor 很重要。
接下来我们进行更新操作。
UPDATE T SET C1 = ‘XX1’ WHERE PK = 1;
在 MySQL 中,更新一个未被索引的列将只会更新存储该行的叶子页的新值。不需要更新其他辅助索引,因为它们都指向没有改变的主键。
而在 PostgreSQL 中,更新一个未被索引的列将生成一个新的元组,可能需要更新所有辅助索引中的新元组 id,因为它们只知道旧的元组 id。这会导致许多写入 I/O。Uber 在 2016 年特别不喜欢这一点,这是他们从 PostgreSQL 转向 MySQL 的主要原因之一。
我在这里说“可能”,是因为在 PostgreSQL 中有一个称为 HOT(heap only tuple,不要与堆组织表混淆)的优化,它在辅助索引中保留旧的元组 id,但在堆页头部放置一个链接,指向旧元组到新元组。
数据类型比较
在 MySQL 中,选择主键数据类型至关重要,因为该键将存在于所有辅助索引中。例如,UUID 主键将使所有辅助索引的大小膨胀,导致更多的存储和读取 I/O。
在 PostgreSQL 中,元组 id 固定为 4 字节,所以辅助索引不会有 UUID 值,只是指向堆的 tids。
Undo logs
所有现代数据库都支持多版本并发控制(MVCC)。在简单的读已提交隔离级别中,如果一个事务 tx1 更新了一行但尚未提交,而另一个并发事务 tx2 想要读取该行,它必须读取旧行而不是更新后的行。大多数数据库(包括 MySQL)都使用撤销日志来实现这一功能。
当事务对一行进行更改时,更改被写入共享缓冲池中的页,所以存储该行的页始终具有最新数据。然后,事务在撤销日志中记录如何撤销行的最新更改的信息(足够的信息来构建旧状态),这样基于它们隔离级别仍需要旧状态的并发事务必须破解撤销日志并构建旧行。
你可能会想,将未提交的更改写入页是否是个好主意。如果后台进程将页刷新到磁盘,然后数据库在事务提交之前崩溃会怎样?这就是撤销日志至关重要的地方。在崩溃后,未提交的更改会在数据库启动时使用撤销日志来撤销。
撤销日志对于长时间运行的事务对其他运行事务的成本是不可否认的。构建旧状态将需要更多的 I/O,且撤销日志可能会满,事务可能会失败。
我曾经看到过一个数据库系统在运行了 3 小时的未提交长事务后,从崩溃中恢复需要超过一个小时。所以要尽量避免长事务。
PostgreSQL 的处理方式完全不同,每次更新、插入和删除都会得到一行的新副本,带有一个新的元组 id,以及关于哪个事务 id 创建了元组和哪个事务 id 删除了元组的提示。因此,PostgreSQL 可以安全地将更改写入数据页,并且并发事务可以根据它们的事务 id 读取旧的或新的元组。
当然,没有哪种解决方案是没有问题的。我们实际上谈到了在辅助索引上创建新元组 id 的成本。此外,PostgreSQL 还需要清除不再需要的旧元组,如果所有运行中的事务 id 都大于删除元组的事务。
进程与线程的对比
MySQL 使用线程,PostgreSQL 使用进程,两者都有利弊。
PostgreSQL 进程架构如下:
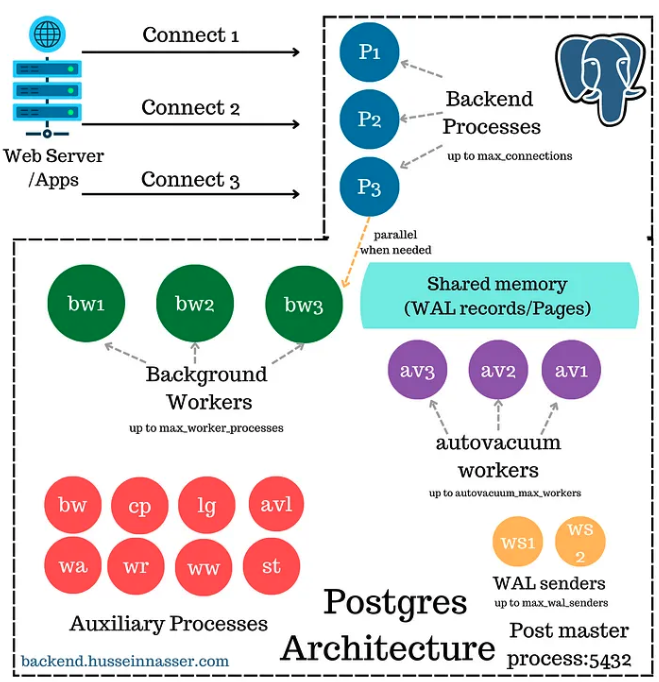
在数据库系统中,我更喜欢线程而不是进程。因为它们更轻量级,并共享其父进程的虚拟内存地址。进程带来了专用虚拟内存和更大控制块(PCB)的开销,相比之下线程控制块(TCB)更小。
如果我们最终还是要共享内存,并处理互斥锁和信号量,为什么不使用线程呢。这只是我的一点小建议。
总结
简而言之,这两个数据库的主要区别实际上归结于主索引和辅助索引的实现方式,以及数据的存储和更新方式。
考虑到这些,你可以选择适合你的数据库系统。真正重要的是分析你的使用场景,了解每种数据库的做法,看看使用那种数据库比较适合。
Share this content